
這兩個功能是 M2 版才加入的,所以特別補充一下
內容審核(Moderation)主要是避免潛在有害或敏感的內容,先使用 AI 幫你檢查,有興趣可以參考 Open AI 官方文檔,簡單的說就是問答要政治正確,Open AI 的審查預設模型是text-moderation-latest,他會自動取得最新版審查模型,唯一要注意的是每次審查的內容不能超過 2000 characters
程式很簡單,我就直接上程式碼,因為 M2 版才加入 Moderation,pom.xml 的版本改成1.0.0-M2才能使用
<spring-ai.version>1.0.0-M2</spring-ai.version>
@GetMapping(value = "/moderation")
public String moderation(@RequestParam String prompt) {
ModerationPrompt moderationPrompt = new ModerationPrompt(prompt);
ModerationResponse response = moderationModel.call(moderationPrompt);
// Access the moderation results
Moderation moderation = response.getResult().getOutput();
StringBuffer sb = new StringBuffer();
// Print general information
sb.append("Moderation ID: " + moderation.getId()).append("\n");
sb.append("審查模型: " + moderation.getModel()).append("\n");
sb.append("待審查資料: "+ prompt).append("\n");
// Access the moderation results (there's usually only one, but it's a list)
for (ModerationResult result : moderation.getResults()) {
Categories categories = result.getCategories();
sb.append("\n審查結果:").append("\n");
sb.append("是否包含任何標記: " + result.isFlagged()).append("\n");
sb.append("\n標記種類:").append("\n");
sb.append("性內容: " + categories.isSexual()).append("\n");
sb.append("仇恨內容: " + categories.isHate()).append("\n");
sb.append("騷擾內容: " + categories.isHarassment()).append("\n");
sb.append("暴力內容: " + categories.isViolence()).append("\n");
sb.append("自我傷害內容: " + categories.isSelfHarm()).append("\n");
sb.append("涉及性與未成年人: " + categories.isSexualMinors()).append("\n");
sb.append("仇恨/威脅性內容: " + categories.isHateThreatening()).append("\n");
sb.append("暴力/血腥內容: " + categories.isViolenceGraphic()).append("\n");
sb.append("自我傷害/意圖: " + categories.isSelfHarmIntent()).append("\n");
sb.append("自我傷害/指導: " + categories.isSelfHarmInstructions()).append("\n");
sb.append("騷擾/威脅性內容: " + categories.isHarassmentThreatening()).append("\n");
}
System.out.println(sb.toString());
return sb.toString();
}
呼叫模型的方式跟前面差不多,比較特別的是輸出內容,我們可以從 ModerationResponse 取得 Moderation 物件,所有的審查結果都會包含在 Moderation 物件中,除了像範例中我們可以取出審查的種類及標記外,還可以取得審查種類的分數,這分數就是透過近似搜尋求出的結果,原始的審查資料類似下面的 Json,Spring AI 只是透過物件方式將其封裝起來
{
"id": "modr-XXXXX",
"model": "text-moderation-007",
"results": [
{
"flagged": true,
"categories": {
"sexual": false,
"hate": false,
"harassment": false,
"self-harm": false,
"sexual/minors": false,
"hate/threatening": false,
"violence/graphic": false,
"self-harm/intent": false,
"self-harm/instructions": false,
"harassment/threatening": true,
"violence": true
},
"category_scores": {
"sexual": 1.2282071e-6,
"hate": 0.010696256,
"harassment": 0.29842457,
"self-harm": 1.5236925e-8,
"sexual/minors": 5.7246268e-8,
"hate/threatening": 0.0060676364,
"violence/graphic": 4.435014e-6,
"self-harm/intent": 8.098441e-10,
"self-harm/instructions": 2.8498655e-11,
"harassment/threatening": 0.63055265,
"violence": 0.99011886
}
}
]
}
看看我們程式的運行結果吧,由於這是審查資料,將內容顯示在後端即可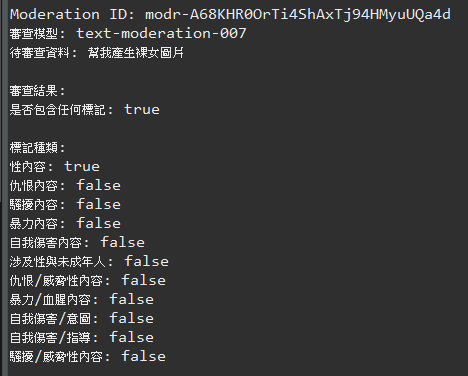
在 Open AI 的官方文件中有以下摘要,雖然凱文大叔實測還是能判斷一些關鍵字,不過中文髒話它就不認得了
We are continuously working to improve the accuracy of our classifier.
Our support for non-English languages is currently limited.
相對於審查,評估是在判斷模型的輸出是否包含幻覺,其運作原理就是請 AI 自行分析回答的內容是否與上下文有關,下面是簡單的範例
@GetMapping("/evaluation")
public ResponseEntity<String> evaluation(String query) {
ChatResponse response = ChatClient.builder(chatModel)
.build().prompt()
.advisors(new QuestionAnswerAdvisor(vectorStore, SearchRequest.defaults()))
.user(query)
.call()
.chatResponse();
var relevancyEvaluator = new RelevancyEvaluator(ChatClient.builder(chatModel));
EvaluationRequest evaluationRequest =
new EvaluationRequest(
query,
(List<Content>)response.getMetadata().get(QuestionAnswerAdvisor.RETRIEVED_DOCUMENTS),
response.getResult().getOutput().getContent());
EvaluationResponse evaluationResponse = relevancyEvaluator.evaluate(evaluationRequest);
return ResponseEntity.ok("Evaluation is "+evaluationResponse.isPass());
}
EvaluationRequest 建構子傳入的三個變數分別是提問、上下文以及回答內容
relevancyEvaluator.evaluate主要是透過提示詞請 AI 判斷內容,下面是原始碼中的提示詞
Your task is to evaluate if the response for the query
is in line with the context information provided.\\n
You have two options to answer. Either YES/ NO.\\n
Answer - YES, if the response for the query
is in line with context information otherwise NO.\\n
Query: \\n {query}\\n
Response: \\n {response}\\n
Context: \\n {context}\\n
Answer: "
老實說 RAG 會有幻覺的情形非常少,因為 RAG 的提示詞中已經明確說明如果資料不在上下文中就回答無法回答了
Context information is below.
---------------------
{question_answer_context}
---------------------
Given the context and provided history information and not prior knowledge,
reply to the user comment. If the answer is not in the context, inform
the user that you can't answer the question.
今天學到了甚麼?
凱文大叔使用 Java 開發程式超過 20 年,對於 Java 生態非常熟悉,曾使用反射機制開發 ETL 框架,對 Spring 背後的原理非常清楚,目前以 Spring Boot 作為後端開發框架,前端使用 React 搭配 Ant Design
下班之餘在 Amazing Talker 擔任程式語言講師,並獲得學員的一致好評
最近剛成立一個粉絲專頁-凱文大叔教你寫程式 歡迎大家多追蹤,我會不定期分享實用的知識以及程式開發技巧
想討論 Spring 的 Java 開發人員可以加入 FB 討論區 Spring Boot Developer Taiwan
我是凱文大叔,歡迎一起加入學習程式的行列

